ROBOTICS
The Case for Human-Swarm Interaction
This piece on "human-swarm interaction" was originally presented at a graduate seminar on bio-inspired multi-agent coordination facilitated by Kirstin Petersen. Animations and visualizations were originally created for the slide presentation,
but have been adapted for the web here.
The term robot, originally invented for a play in 1920, was derived from the Slavic word robota, which literally means drudgery or forced labor. Today, 100 years after the word robot first came into our vocabulary, although the physical form of robots has definitely evolved, the relationship between humans and robots in the real world has largely been the same, insofar as robots aim to support our endeavors by automating repetitive low-level tasks and acting as physical extensions of ourselves. Human-robot interaction is more or less a one-to-one relationship. We do something and the robot does something in response. But in interacting with single robots, we can only do so much. We are, of course, no stranger to the immense power of the swarm. We know that swarms possess power in numbers. And because of their distributed, often decentralized nature, swarms afford us much further reach in tasks such as urban search and rescue. It makes sense that the conversation in recent years has shifted from human-robot interaction to human-swarm interaction (HSI).
It seems straightforward to project ourselves and our intentions onto single robots. What is arguably less apparent is how to make swarms work for and with us. Because any changes made at the local level are bound to have some emergent global effect, the ways by which we impose these swarm control methods matter and make a big difference.
Kolling et al.

In their paper, Kolling and others describe two ways in which us humans can interact with swarms in a foraging mission. To explore HSI, the authors created a virtual swarm and implemented it on a virtual testbed. They then asked 32 students to play a game and use the swarm to accomplish a mission.
The Mission
Control Methods
There are two kinds of control methods with which human operators are able to interact with certain swarm agents to carry out some prescribed action. The first kind is called intermittent control, where a human operator performs a one-time assignment of some algorithm onto a group of agents of their choosing. This kind of control is persistent through time because the agents maintain their assigned mode as they propagate throughout the swarm. In the testbed this is realized by selection control; the authors use a selection tool to select robots.The second kind is called environmental control. Unlike the active influence of intermittent control, environmental control controls agents by changing their environment, exerting passive influence on nearby agents. This is realized by beacon control, where users can place beacons and set a radius of influence. Simple leader-predator models can be simulated by beacon control. When you program the beacon to attract agents, it’s a leader. When you program the beacon to repel agents, it’s a predator.
Human Control Algorithms
The authors made six algorithms, or modes, available to the human operators. Using either selection or beacon control, the human operators can impose these modes on a subset of the swarm. Note that the agents are set to move randomly (see A-1. Random Motion) by default. The Deploy and Rendezvous modes require a bit more explanation.The purpose of the deploy algorithm is to distribute agents uniformly throughout a space. It does this by iteratively calculating Voronoi tessellations with each agent’s current position as the generating point for each facet. This algorithm will converge to what’s called a centroidal Voronoi tessellation over time.
In the rendezvous algorithm, agents mutually agree on a meeting place. And they must agree on one such that they don’t break line-of-sight communication links. One way to accomplish this is by using the
circumcenter algorithm, where each agent computes the circumcenter of itself and its neighbors. The circumcenter is defined as the smallest circle containing all agents. By iterating this algorithm, communication links will be maintained
and agents will eventually converge to the center of that circle.
Autonomous Swarm Algorithms
The authors also created five autonomous swarm algorithms to compare with the performance of human operators.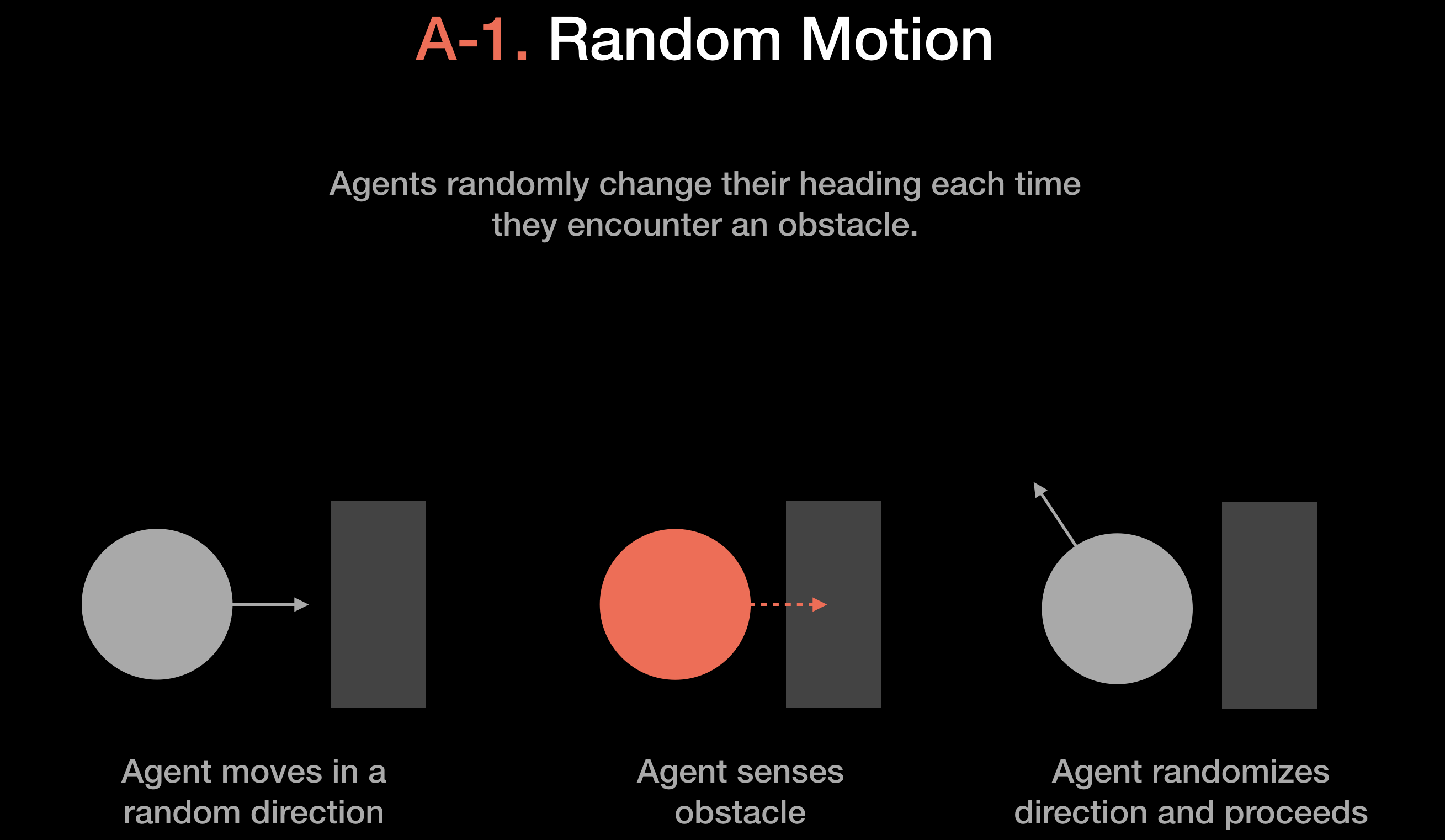 The simplest autonomous algorithm is based on random motion. Recall that this is the default mode for the agents in human operator mode.
The simplest autonomous algorithm is based on random motion. Recall that this is the default mode for the agents in human operator mode.
A second autonomous algorithm uses random motion, but overrides this random motion when it encounters an information object. When an information object invades its sensing radius, it will stop what it’s
doing, and collect information from that object. This algorithm may be seen as a comparable baseline to human performance.
A variant of the "A-3. Potential Field" algorithm drops the attracting term due to information objects, and instead executes a special case when it encounters an information object. Upon detecting an information
object, the agent will send out a message that will attract up to 10 nearby robots.
This fifth one is interesting. We studied pheromones in the context of establishing a trail to collect stuff, and bring them back to a base. But in this case, the agents don’t have to return to a base,
they simply transmit the stuff they collect. Here, they use pheromones to explore obstacles more effectively. Pheromones are not used as an attractant, rather, as a deterrent. Upon encountering an obstacle, an agent hugs the boundary
to the right while depositing pheromones. So when another agent encounters the same obstacle, it takes the road less travelled by. The pheromone trails decay after around 8 seconds.
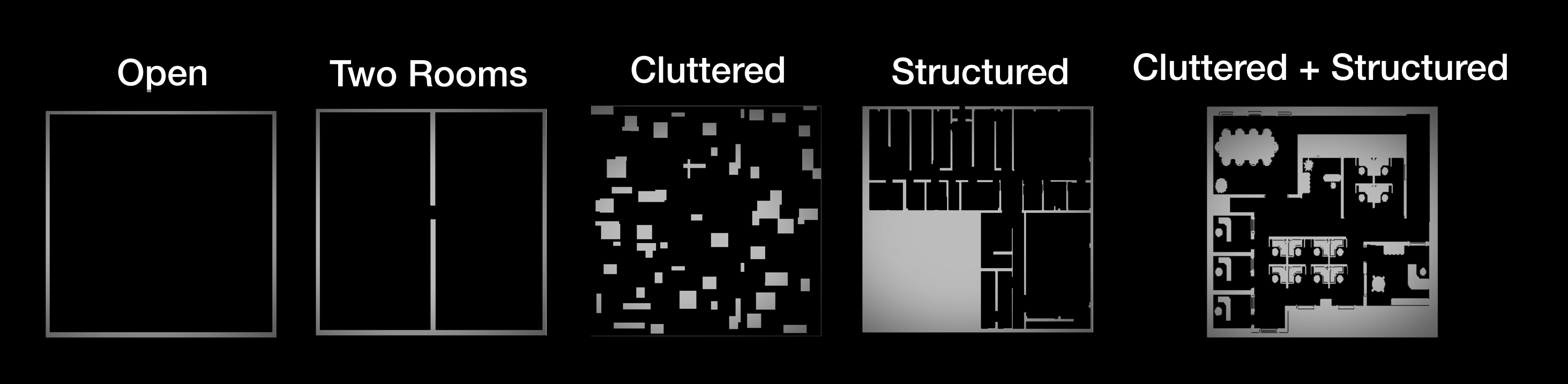
Human operator and autonomous swarm trials were carried out for swarms of varying size (50 to 200 robots) in five maps.
Test Results
Scalability
Taking a look at scalability, we see that the autonomous algorithms, though their performances varied, largely remained robust to swarm size. Comparing the two kinds of human-swarm interaction, we see that selection control performs better in all scenarios, and scales better than beacon control. This is contrary to the authors’ original hypothesis that beacon control will be better. After reviewing the command logs, the authors came to the following conclusion. Beacon control should be more scalable in theory. So why isn’t it? The reason cited in the paper is that beacon control “requires more operator training,” than selection control.Map Complexity
The next thing we’re going to look at is map complexity. How do the different kinds of human interaction and autonomous swarms perform in more complex environments?For humans, not so good. Humans are outperformed by autonomous swarms across the board. For the simpler maps, it is actually better for the human to not do anything at all then to intervene. Now to be fair, human operators did beat out 3 of the 5 autonomous swarms in the complex maps, but two of the autonomous algorithms, the ones based on the potential fields, consistently performed far better than human operators in complex environments. To recap, we found that of the two methods for human operation, selection control scales better than beacon control. And human operators perform worse than autonomous agents. The case for human-swarm interaction is not looking that good. Until we look at that last chart again, very closely.
Making the Case for HSI
Do you notice something interesting going on with the human operators? Look how little our performance varies in complex environments. These results suggest that although we are outperformed by the autonomous algorithms, we adapt much better to increasingly complex environments.This fact represents the foremost case for involving humans in autonomous swarms: our capacity for situational awareness, our ability to adapt in the face of complexity and unforeseen errors. In fact, citing the Kolling paper, other studies recommend not placing humans in the role of operators, as was done here, but in a more supervisory role.
This particular study explored humans fulfilling the role of operator. But when humans and autonomous swarms are working together at a low level, it may be tempting to punch up the autonomy of the swarm component. Initially this would make sense, right? After all, more autonomy lightens the load on humans. But a recent 2018 paper by Hussein and Abbass titled “Mixed Initiative Systems for Human-Swarm Interaction” warns against this:
Flexible Autonomy
What does all this teach us about human-swarm interaction? Designing an effective human-interactive swarm, especially one suited to foraging or search-and-rescue missions, has to do with assigning the human a more supervisory role at a higher level. In addition to humans as supervisors, the Kolling paper demonstrates the merits of having human operators-in-the-loop to guide low-level autonomous agents. In the latter case, the performance of the system hinges on finding the right level of autonomy to supplement human situational awareness. Too little and the human won’t physically be able to carry out the mission. Too much and the human loses their situational awareness about the mission.Even if we do find the right measure of autonomy, even this might not be enough, because as long as the level of autonomy is fixed, studies have shown that this is associated with complacency and the performance of the system may deteriorate with a human-in-the-loop. There is an elegant and robust solution to this problem. It involves incorporating flexible autonomy by creating a closed-loop feedback control system that modulates the autonomy parameters of a swarm depending on a set of indicators. The Hussein and Abbass paper provides a very rough example of what such a system might look like.
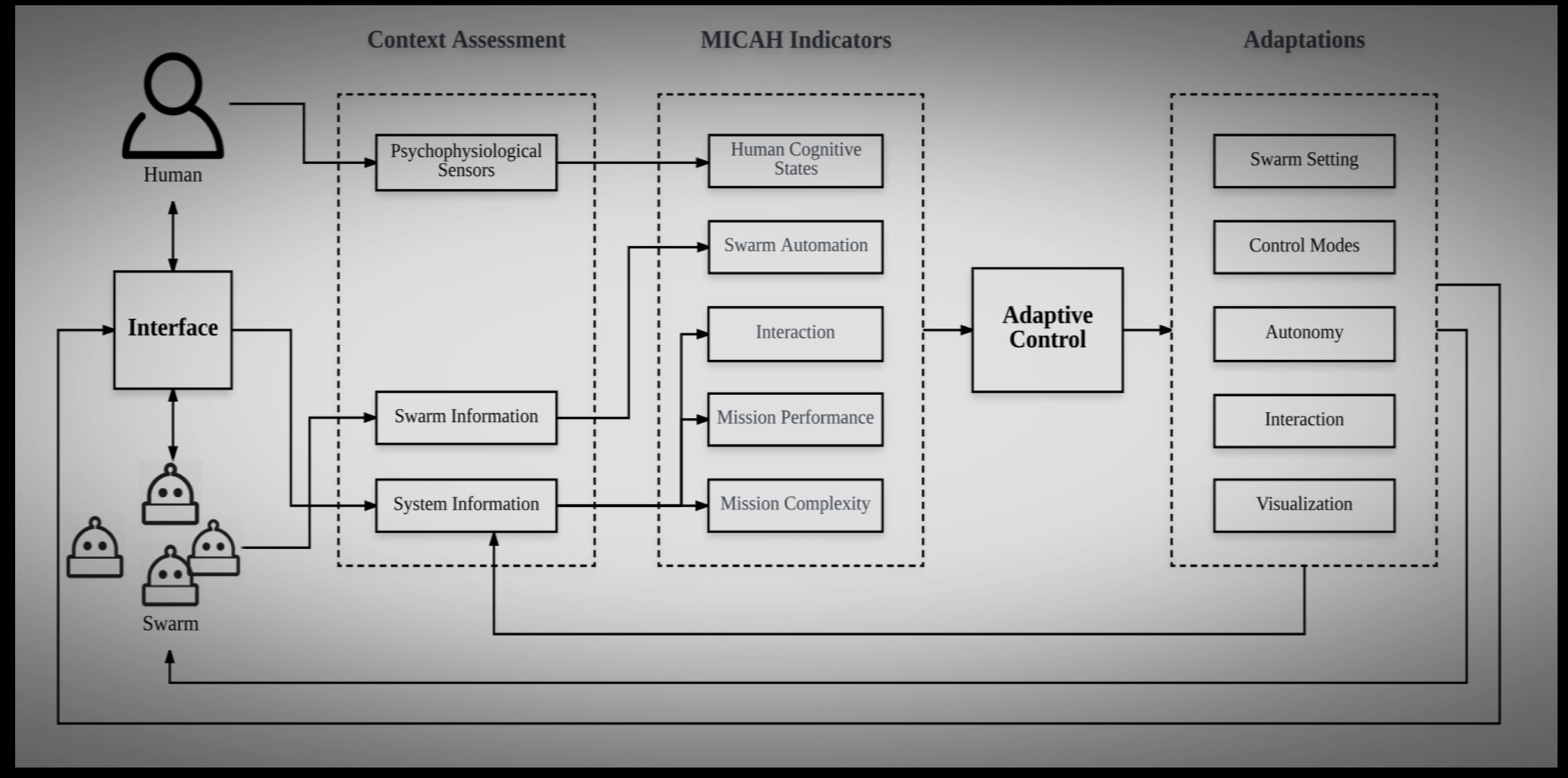
Exactly what those indicators are remains to be seen. They may include metrics on swarm performance and even heart rate and EEG sensors to determine whether the human operator is overwhelmed or complacent. This is an exciting, open question being investigated in HSI.
I want to end on this note of flexible autonomy because that seems to be where the field is at today. Again, this is all emergent research so I don’t believe there has yet been experimental implementation of this idea of flexible autonomy. From what I’ve seen, the original scope of the Kolling paper seems to be one of the most comprehensive experimental testbeds to do with human-swarm interaction to date. Nevertheless, this idea of flexible autonomy seems to me like a worthwhile extension to the Kolling paper, as well as other current models of human-interactive swarms.
